
経緯
現在開発、テスト実施中のS部品様の案件にて、テスト実施中に発生した問題と解決策を自分のメモかつ別案件で同じことが発生したときのために発表しようと思った。
発生した問題
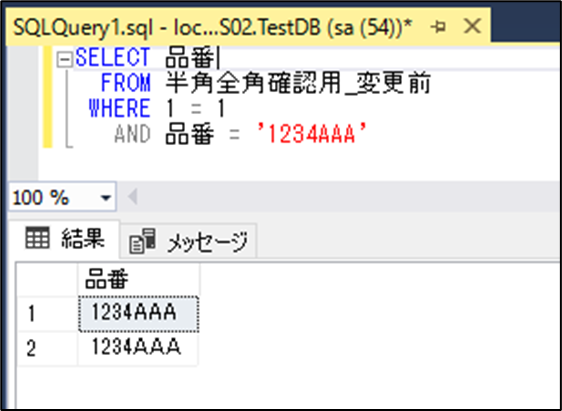
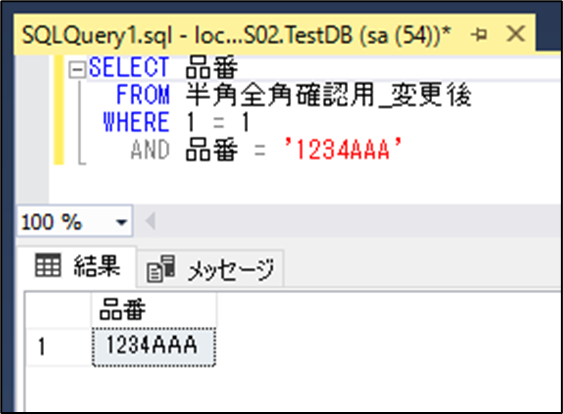
同じようなデータで半角と全角が混ざっているデータと半角のみのデータが混在しており、全角と半角の区別がSQL Server上ではされず、ソートが正しく行われないため、プログラム上(C#)でエラーが発生
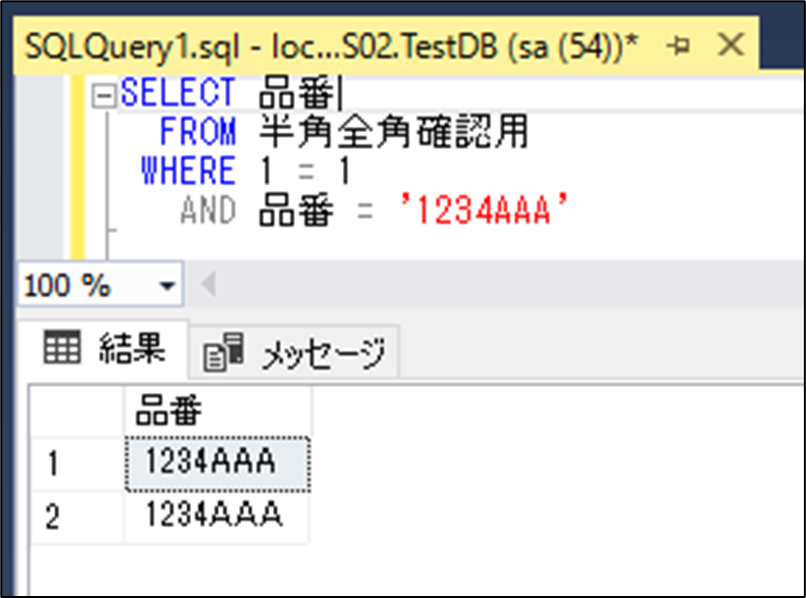
解決策
1.検索条件に照合順序を指定し半角と全角を判別する
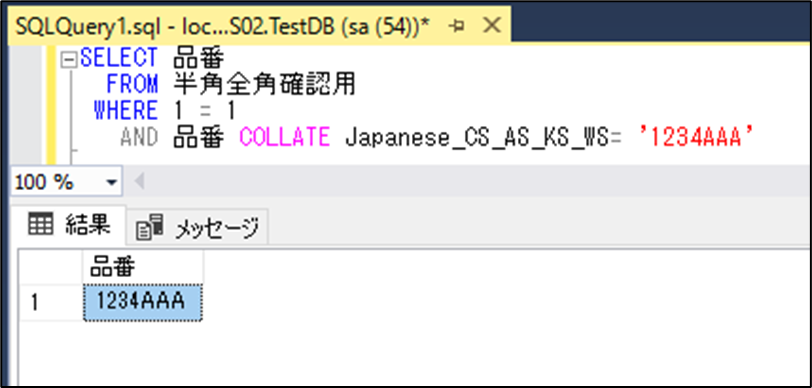
- 大文字と小文字の区別は「Case」の「C」
- アクセント(濁音、半濁音の有無)の区別は「Accent」の「A」
- ひらがなとカタカナの区別は「Kana」の「K」
- 全角と半角の区別は「Width」の「W」
- 区別する場合は「Sensitive」の「S」
- 区別しない場合は「Insensitive」の「I」
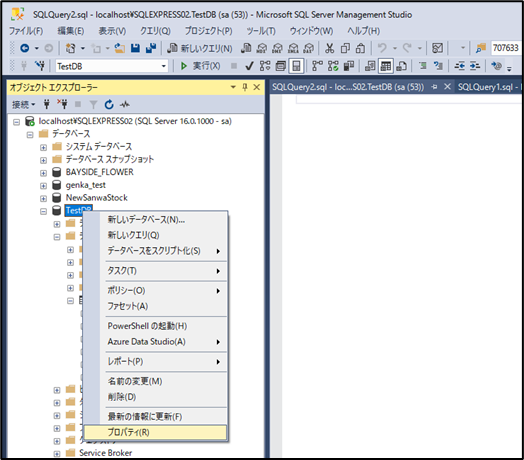
2.DBの設定を変更し半角と全角を判別する
設定方法
① 対象のDBを右クリックしプロパティを選択
② ページの選択から「オプション」を選択
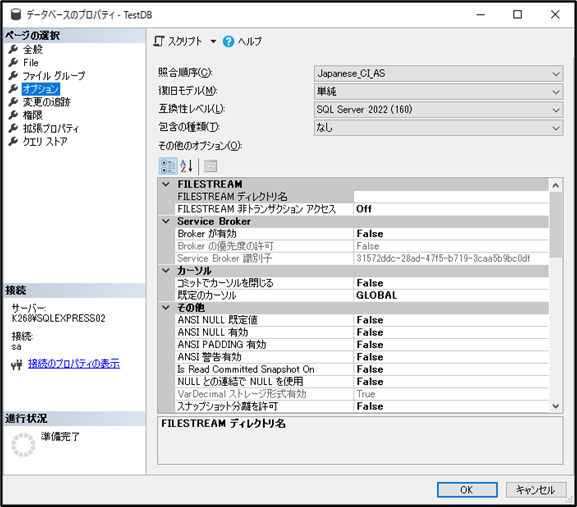
③ 照合順序から設定
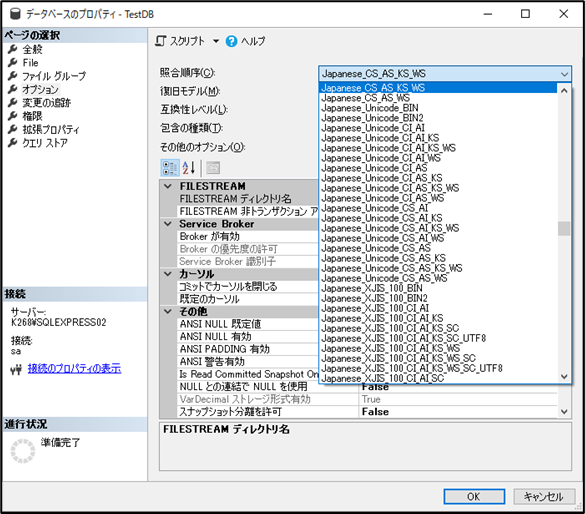
※照合順序の設定前にCREATEしたテーブルは設定が反映されないため注意
まとめ
設定ひとつで変更できることを知れたのは、今後の開発にも役に立つ知識だと思う。今後も知らなかったことなどは自身のメモのためにも、朝会などで発表し、まとめておこうと感じた。また今回はSQL Serverに関してのみの設定だったため、他のDBでの設定方法を確認しておこうと思った。
参照

レコードの検索時に照合順序を指定(大文字と小文字、全角と半角などを区別せずに検索)[SQL Server]
システムの制約上、全テーブルのデータ型が文字列のすべての列の照合順序がバイナリ(Japanese_BIN)になっている場合があります。バイナリでは大文字と小文字、全角と半角などは、すべて別の文字として照合されます。コード値などはバイナリで完
johobase.com

照合順序と Unicode のサポート - SQL Server
SQL Server での照合順序と Unicode のサポートについて学習します。
learn.microsoft.com


コメント